
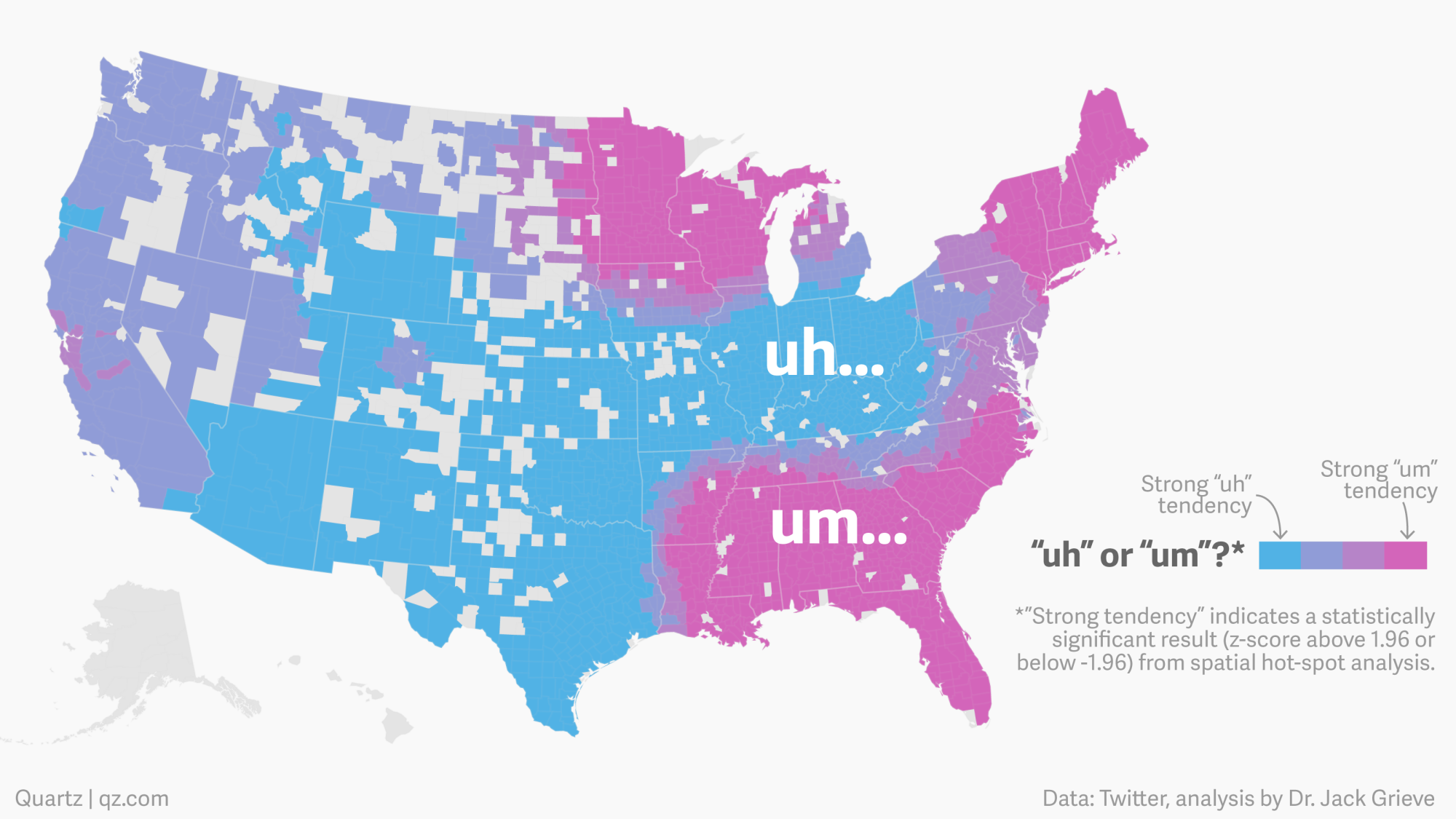
The map above shows a preliminary attempt to use the tremendous amount of linguistic data being produced on the web to understand how language works. Jack Grieve, a forensic linguist at Aston University in the UK, has been looking through 6 billion words collected from Twitter. Following a discussion with fellow linguist Mark Lieberman—a prolific blogger who has long been interested in the “um”/”uh” divide—Grieve decided to look through his corpus of tweets to see how the two words compared. They started their exploration with data from America.
2 Responses to Archaeology of New Media